Video Scraper for YouTube and PluralSight
09 Apr 2017
In this article, I will talk about how to download from YouTube or Plurasight. The very beginning motivation of doing such things is that I will go back into the Great Fire Wall of China and cannot continuously enjoy the benefits of the free-access outside the wall.
My first look is upon how to download the Video from YouTube, although it’s break the regulation and being considered as a kind of stealing, but from the technical perspective I just want to know if it’s possible.
Vget for YouTube:
Although there are loads of plugins for Chrome browser you can use to download videos from YouTube, like this
one saveFrom Hleper which I’m using.
It’s quite versatile, not only for YouTube,but also for any online video-site else and quite well get along with the browser.
Just like this:
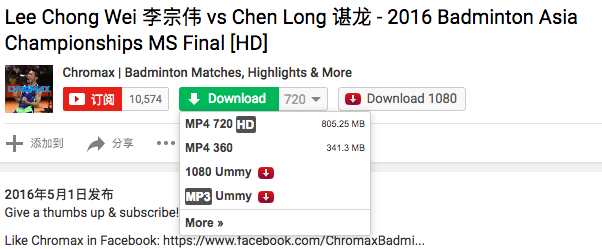
Two new buttons attached on the page. However, the shortage is that you have to manually download the videos one by one. If you want to download a channel’s all videos the arduous work emerged. ———– What I want it is using the YouTube API to retrieve all the videos’ address and input them into program and analysis their addresses and download. After searching in Google, I found Vget Home which is what I want. You can read through examples list on that page. Essentially, this lib using YouTubeParser.java to extract video link via matching regex.
// grab html5 player url
{
Pattern playerURL = Pattern.compile("(//.*?/player-[\\w\\d\\-]+\\/.*\\.js)");
Matcher playerVersionMatch = playerURL.matcher(html);
if (playerVersionMatch.find()) {
info.setPlayerURI(new URI("https:" + playerVersionMatch.group(1)));
}
}
....
....
// stream video
Pattern encodStream = Pattern.compile("stream=(.*)");
Matcher encodStreamMatch = encodStream.matcher(url_encoded_fmt_stream_map);
if (encodStreamMatch.find()) {
String sline = encodStreamMatch.group(1);
String[] urlStrings = sline.split("stream=");
for (String urlString : urlStrings) {
urlString = StringEscapeUtils.unescapeJava(urlString);
Pattern link = Pattern.compile("(sparams.*)&itag=(\\d+)&.*&conn=rtmpe(.*),");
Matcher linkMatch = link.matcher(urlString);
if (linkMatch.find()) {
String sparams = linkMatch.group(1);
String itag = linkMatch.group(2);
String url = linkMatch.group(3);
url = "https" + url + "?" + sparams;
url = URLDecoder.decode(url, WGet.UTF8);
filter(sNextVideoURL, itag, new URL(url));
}
}
}
The url would be the real video link you want, then the program will download it via multi-thread lib wget That will make your life easier.
PhantomJS, CasperJS and Selenium for PluralSight
Actually, I’m not a tester, but it’s really helpful if you utilize some auto-testing tools to do some dirty work for you, such as PhantomJS, CasperJS or Selenium. They are all for make JS rendered Website tested easier, before I touching them. What I only know about web scraping is mainly on static html parser,like Jsoup or BeautifulSoup. But they will be useless if you are facing a website which renders its page by JS,especially Single Page Application (SPA). They are quite common approached by AngularJS or React.
Essentially ,PhantomJS and CasperJS are the same thing. CasperJS is a more convinent wrapper for PhantomJS and they are all headless testing JavaScript lib working on CLI. Better to use CasperJS as its more succinct than PhantomJS. I will show some code here:
var page = require('webpage').create();
page.settings.javascriptEnabled = true;
phantom.cookiesEnabled = true;
phantom.javascriptEnabled = true;
console.log('The default user agent is ' + page.settings.userAgent);
var steps = []
var testindex = 0;
var loadInProgress = false;
steps = [
function () {
page.open('https://app.pluralsight.com/id?redirectTo=/', function (status) {
if (status !== 'success') {
console.log('Unable to access network in step 1');
} else {
page.evaluate(function () {
console.log("login...")
document.getElementById('Username').value = 'username';
document.getElementById('Password').value = 'password';
document.getElementById('login').click();
});
}
});
},
function () {
page.open('https://app.pluralsight.com/library/courses/java2/table-of-contents', function (status) {
page.includeJs('http://ajax.googleapis.com/ajax/libs/jquery/1.7.2/jquery.min.js', function () {
if (status !== 'success') {
console.log('Unable to access network in step 2');
} else {
page.evaluate(function () {
var allList = $('.l-course-page__content')
console.log("rendering...", allList.length)
var videoList = allList.find('a')
console.log("videoList", videoList.length)
videoList.each(function () {
var video_page_href = $(this).attr("href")
if (video_page_href) {
console.log(video_page_href)
console.log("video element=",$(this))
// $(this).click()
console.log("after click video element=",$(this))
return false // same as break
}
})
});
}
})
})
},
function () {
page.open('https://app.pluralsight.com/player?course=java2&author=john-sonmez&name=java2-m1-exceptions&clip=0&mode=live', function (status) {
})
},
function () {
page.includeJs('http://ajax.googleapis.com/ajax/libs/jquery/1.7.2/jquery.min.js', function () {
page.evaluate(function () {
//show video link
console.log('video object =', $('video').html());
console.log('video link =', $('video').attr('src'));
console.log('main html =', $('html').html());
});
page.render("newpage1.png");
phantom.exit();
});
}
]
//Execute steps one by one
interval = setInterval(executeRequestsStepByStep, 10000);
function executeRequestsStepByStep() {
if (loadInProgress == false && typeof steps[testindex] == "function") {
console.log("step " + (testindex + 1));
steps[testindex]();
testindex++;
}
if (typeof steps[testindex] != "function") {
console.log("test complete!");
}
}
page.onLoadStarted = function () {
loadInProgress = true;
console.log('Loading started');
};
page.onLoadFinished = function () {
loadInProgress = false;
console.log('Loading finished');
};
page.onConsoleMessage = function (msg) {
console.log(msg);
};
These code segment shows that several steps defined, like login, open course home page and each video page and execute them one by one by interval 10 seconds. However, it cannot extract the real video address unfortunately.
Neither does CapserJS unexpectedly as they are the same thing. Even though the code is mush shorter, and pass in the callback and waiting for the resource rendered in page.
var casper = require('casper').create({
verbose: true,
logLevel: "info"
});
var links;
// Opens login page
casper.start('https://app.pluralsight.com/id');
//login
casper.waitForSelector('form', function () {
this.fillSelectors('form', {
'input[name="Username"]': 'username',
'input[name="Password"]': 'password'
}, true);
});
// var url = 'https://app.pluralsight.com/library/courses/java2/table-of-contents'
var url = 'https://app.pluralsight.com/player?course=java2&author=john-sonmez&name=java2-m1-exceptions&clip=2&mode=live'
casper.then(function () {
casper.start(url).then(function () {
casper.waitForSelector("#vjs_video_3",function(){
this.click('#vjs_video_3')
casper.waitFor(function check() {
return this.evaluate(function(){
//until find the video eleme nt
this.echo(this.getHTML('video',true))
//cannot get video url....
return document.getElementsByTagName('video').getAttribute('src')
})
},function then(){
this.captureSelector('video.png', 'video');
},function ontTimeout(){
this.echo("Time out...")
},150000,{})
})
})
});
casper.run(function () {
for (var i in links) {
console.log(links[i]);
}
casper.exit();
});
Above code is not workable in terms of video address analysis, list here only for my future reference.
Finally, I have turn to Selenium, which is quite powerful tool to simulate the real user operation. It’s powered by a WebDriver, which almost all modern browsers support to. Only thing to do is setup for the web driver and tell the program where it is you installed and Maven dependency Here I’m using ChromeDriver. This code is just for analysis of video address, you can by whatever means to download it. Just make sure don’t use multi-thread download, as PluralSight will ban your account if they spot abnormal dataflow.
Happy Hacking.
pom.xml
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.3.0</version>
</dependency>
Scraper code:
package selenuimScraper;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.openqa.selenium.By;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.*;
public class SeleScraper {
//keep the order
static Map<String, String> fileName2Src = new LinkedHashMap<>();
static Set cookieSet;
static String courseURL = "https://app.pluralsight.com/library/courses/springmvc-intro/table-of-contents";
static String driverLocation = "/pathto/chromedriver";
static String username = "username";
static String password = "password";
static WebDriver parent_driver;
static boolean firstHandleCookie = true;
public static void main(String[] args) throws InterruptedException {
System.setProperty("webdriver.chrome.driver", driverLocation);
login();
String courseName = getVideoList();
for (Map.Entry<String, String> f2c : fileName2Src.entrySet()) {
if (!openVideo(f2c.getKey(), f2c.getValue())) {
System.out.println("cookie expired, login again and retry for " + f2c.getKey() + " " + f2c.getValue());
relogin();
//try again
openVideo(f2c.getKey(), f2c.getValue());
}
}
parent_driver.quit();
writeToFile(courseName);
}
private static void relogin() throws InterruptedException {
firstHandleCookie = true;
parent_driver.quit();
login();
}
private static String getVideoList() throws InterruptedException {
System.out.println("getVideoList....");
parent_driver.get(courseURL);
Thread.sleep(3000);
WebElement titleElement = parent_driver.findElement(By.xpath("//*[@id=\"ps-main\"]/div/div/section/div[1]/div[2]/h1"));
String courseName = titleElement.getText();
List elements = parent_driver.findElements(By.cssSelector("a.table-of-contents__clip-list-title"));
//have to use jsoup to get invisible videos' titles
Document doc = Jsoup.parse(parent_driver.getPageSource());
Elements videoList = doc.select("a.table-of-contents__clip-list-title");
for (int i = 0; i < videoList.size(); i++) {
//using i to make key different
fileName2Src.put(i+"_"+videoList.get(i).html(), elements.get(i).getAttribute("href"));
}
return courseName;
}
private static void login() throws InterruptedException {
System.out.println("Login....");
parent_driver = new ChromeDriver();
parent_driver.get("https://app.pluralsight.com/id");
Thread.sleep(3000); // Let the user actually see something!
WebElement usernameEle = parent_driver.findElement(By.xpath("//*[@id=\"Username\"]"));
WebElement passwordEle = parent_driver.findElement(By.xpath("//*[@id=\"Password\"]"));
usernameEle.sendKeys(username);
passwordEle.sendKeys(password);
passwordEle.submit();
parent_driver.get("https://app.pluralsight.com/library");
cookieSet = parent_driver.manage().getCookies();
}
private static boolean openVideo(String fileName, String videoPage) throws InterruptedException {
System.out.println("openVideo src " + videoPage);
if (parent_driver == null) {
System.out.println("init video driver...");
parent_driver = new ChromeDriver();
}
parent_driver.get(videoPage);
Thread.sleep(3000);
WebElement video = parent_driver.findElement(By.xpath("//*[@id=\"vjs_video_3_html5_api\"]"));
//if video is null, may need to login
String video_src = video.getAttribute("src");
if (video_src == null || video_src.length() == 0) {
System.out.println("Quit video driver...");
parent_driver.quit();
return false;
}
//overwrite value to true video url
fileName2Src.put(fileName, video_src);
return true;
}
private static void writeToFile(String courseName) {
System.out.println("begin to write src to file "+courseName);
try (BufferedWriter bw = new BufferedWriter(new FileWriter(courseName))) {
for (Map.Entry<String, String> src : fileName2Src.entrySet()) {
bw.write(src.getKey() + "=#=" + src.getValue() + "\n");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
</pre>